Decision Tree Is Supervised Or Unsupervised
De vraag of een beslissingsboom een supervised (begeleide) of unsupervised (onbegeleide) leermethode is, leidt soms tot verwarring. Het antwoord is echter vrij helder: een beslissingsboom is een supervised learning algoritme. Om dit goed te begrijpen, is het essentieel de basisprincipes van beide leermethoden te kennen en te bekijken hoe een beslissingsboom precies werkt.
Supervised vs. Unsupervised Learning: De Basis
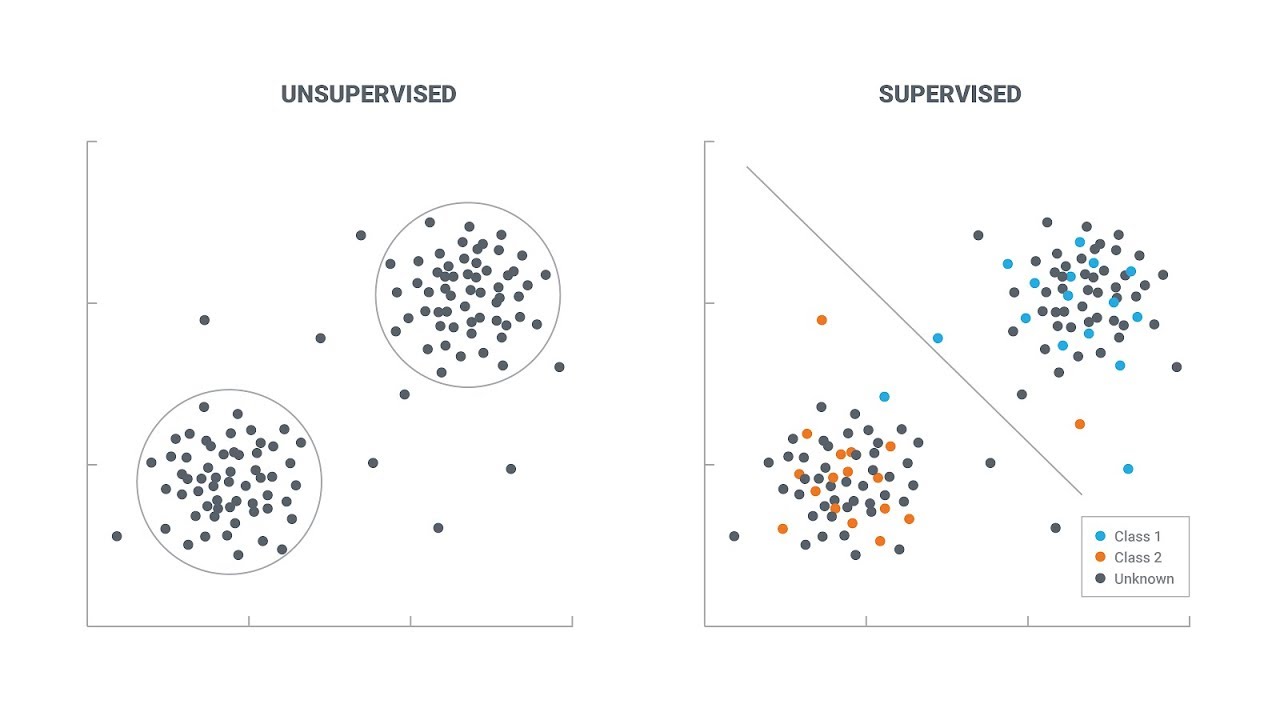
Het fundamentele verschil tussen supervised en unsupervised learning ligt in de aanwezigheid van gelabelde data. Supervised learning gebruikt gelabelde data, wat betekent dat elk datapunt een bijbehorende output of target-variabele heeft. Het doel is om een model te trainen dat deze labels correct kan voorspellen op basis van de input features. Denk aan een dataset met foto's van katten en honden, waarbij elke foto gelabeld is als 'kat' of 'hond'. Het algoritme leert de patronen die katten en honden onderscheiden en kan vervolgens nieuwe, ongelabelde foto's correct classificeren.
Unsupervised learning daarentegen werkt met ongelabelde data. Er is geen vooraf gedefinieerde output. Het doel is om structuur in de data te ontdekken, bijvoorbeeld door data te clusteren in groepen met vergelijkbare kenmerken of door patronen en relaties te vinden. Denk aan een dataset met klantgegevens zonder labels. Een unsupervised learning algoritme kan klanten segmenteren op basis van hun koopgedrag, zonder dat het vooraf weet welke segmenten er bestaan.
Waarom Decision Trees Supervised zijn
Beslissingsbomen gebruiken gelabelde data om een model te bouwen dat beslissingen neemt op basis van een reeks vragen. Het trainingsproces omvat het vinden van de beste manier om de data te splitsen op basis van de input features om de outputvariabele zo goed mogelijk te voorspellen. Deze splitsingen worden gemaakt op basis van criteria zoals Gini impurity of information gain, die de homogeniteit van de labels binnen elke subgroep meten.
Elke node in de boom representeert een test op een attribuut (feature). De takken die uitgaan van een node vertegenwoordigen de mogelijke uitkomsten van de test. Het pad van de wortel naar een blad node vertegenwoordigt een reeks beslissingen die leiden tot een voorspelling. Het blad van de boom bevat de voorspelling voor een bepaalde input.
Voorbeeld: Stel je voor dat we een beslissingsboom willen bouwen om te voorspellen of een klant een lening zal terugbetalen. De dataset bevat kenmerken zoals inkomen, kredietscore, leeftijd en of de klant al eerder een lening heeft gehad. De outputvariabele is of de lening is terugbetaald (ja/nee). De beslissingsboom zal de data splitsen op basis van deze kenmerken om groepen klanten te creëren die een hogere of lagere kans hebben om de lening terug te betalen. De boom 'leert' dus van de gelabelde data om toekomstige leningen te beoordelen.
De Rol van Labels in het Trainingsproces
Het trainingsproces van een beslissingsboom is cruciaal voor het begrijpen van de supervised aard. Het algoritme evalueert verschillende splitsingen op basis van de input features en kiest de splitsing die de grootste verbetering in de voorspelling van de outputvariabele oplevert. Zonder de labels (de outputvariabele) zou het onmogelijk zijn om te bepalen welke splitsingen 'goed' zijn en welke niet. Het algoritme heeft een 'gouden standaard' nodig om zijn prestaties te meten en te verbeteren.
Denk hieraan: Een unsupervised algoritme zoals k-means clustering zou de klantgegevens kunnen gebruiken om groepen klanten te vormen op basis van hun kenmerken, maar het zou niet kunnen voorspellen of een specifieke klant een lening zal terugbetalen. Dit komt omdat k-means geen informatie heeft over de terugbetalingsstatus van de lening. De labels zijn essentieel voor de voorspellende kracht van de beslissingsboom.
Data voorbeelden en Beslissingsbomen
Laten we enkele concrete voorbeelden bekijken om het verschil tussen supervised en unsupervised learning verder te illustreren en te laten zien hoe beslissingsbomen in supervised scenario's passen:
- Supervised Learning (Decision Tree):
- Dataset: Medische data met kenmerken van patiënten (leeftijd, bloeddruk, cholesterolniveau, etc.) en een label dat aangeeft of de patiënt een hartziekte heeft (ja/nee).
- Doel: Bouw een beslissingsboom die kan voorspellen of een nieuwe patiënt een hartziekte heeft op basis van zijn/haar kenmerken.
- Beslissingsboom werking: De boom splitst de data op basis van de kenmerken, bijvoorbeeld eerst op basis van leeftijd (is de patiënt ouder dan 55 jaar?), vervolgens op basis van bloeddruk (is de bloeddruk hoger dan 140/90?), etc. Uiteindelijk leidt elk pad in de boom tot een voorspelling: "hartziekte" of "geen hartziekte".
- Unsupervised Learning (K-Means Clustering):
- Dataset: Klantgegevens van een webwinkel (aantal bezoeken, bestede bedrag, gekochte producten, etc.) zonder labels.
- Doel: Segmenteer de klanten in groepen met vergelijkbare koopgedragingen.
- K-Means werking: K-means algoritme deelt de klanten op in K clusters (bijvoorbeeld 3 clusters: "grote bestellers", "frequente bezoekers", "incidentele kopers") op basis van hun kenmerken. De webwinkel kan deze segmenten gebruiken om gerichte marketingcampagnes te ontwikkelen.
Nog een voorbeeld: Spamdetectie
Bij spamdetectie in e-mail gebruiken we een supervised learning aanpak, vaak met een beslissingsboom of een ander classificatiealgoritme. De trainingsdata bestaat uit e-mails die gelabeld zijn als 'spam' of 'geen spam' (ook wel 'ham' genoemd). De kenmerken die gebruikt worden om een e-mail te classificeren, kunnen onder andere het aantal woorden in de e-mail, de aanwezigheid van bepaalde woorden (zoals 'viagra' of 'gratis'), de afzender van de e-mail, en de aanwezigheid van links bevatten. De beslissingsboom leert welke combinaties van kenmerken sterk correleren met spam, en kan vervolgens nieuwe, ongelabelde e-mails classificeren.
Complexiteit en Nuances
Hoewel de basisprincipes van supervised en unsupervised learning vrij duidelijk zijn, zijn er enkele nuances die belangrijk zijn om te begrijpen. Semi-supervised learning is een hybride aanpak die gebruik maakt van zowel gelabelde als ongelabelde data. Dit kan nuttig zijn wanneer het verzamelen van labels duur of tijdrovend is. Er zijn ook technieken zoals self-supervised learning, waarbij het model labels genereert uit de ongelabelde data zelf, om vervolgens op die data te trainen.
Het is ook belangrijk te benadrukken dat de keuze van het juiste algoritme afhangt van de specifieke problematiek en de beschikbare data. Een beslissingsboom is een krachtig algoritme voor classificatie- en regressieproblemen, maar het is niet altijd de beste keuze. Andere algoritmen, zoals support vector machines (SVM's) of neurale netwerken, kunnen in bepaalde situaties betere resultaten opleveren.
Een ander belangrijk aspect is feature engineering, het proces van het selecteren en transformeren van de input features. Goede feature engineering kan de prestaties van een beslissingsboom aanzienlijk verbeteren. Het is belangrijk om features te kiezen die relevant zijn voor de outputvariabele en om te voorkomen dat er features zijn die sterk gecorreleerd zijn met elkaar (multicollineariteit), wat de boom kan verstoren.
Conclusie
Samenvattend is een beslissingsboom een duidelijk voorbeeld van een supervised learning algoritme. Het vereist gelabelde data om te trainen en een model te bouwen dat de relatie tussen input features en outputvariabelen kan voorspellen. Zonder de labels zou het algoritme niet in staat zijn om de beste splitsingen te vinden en een accurate voorspelling te doen. Het begrijpen van dit fundamentele principe is essentieel voor het effectief toepassen van machine learning technieken.
Oproep tot actie: Experimenteer zelf met beslissingsbomen! Gebruik een dataset met gelabelde data en probeer een beslissingsboom te trainen met behulp van een library zoals scikit-learn in Python. Kijk hoe de boom zich gedraagt met verschillende parameters en probeer de performance te verbeteren. Door zelf te experimenteren, krijg je een dieper inzicht in de werking van beslissingsbomen en de principes van supervised learning.

Bekijk ook deze gerelateerde berichten:
- Disneyland Paris The Tower Of Terror
- Mondriaanhuis Kortegracht 11 3811 Kg Amersfoort
- Inwendige Herniatie Na Gastric Bypass
- Hoeveel Mg Cafeïne In Red Bull
- Grote Pedagogen In Klein Bestek
- Wie Ben Ik Spel Maken
- Wie Was 7 Keer Premier Van Italië Negen Letters
- Movies On Vincent Van Gogh
- Wat Maakt Deel Uit Van Je Digitale Voetafdruk
- The Fault In Our Stars Summary