Ordinal Nominal And Scale In Spss
In de wereld van de statistiek is het cruciaal om te begrijpen welke soorten data je hebt. De type data bepaalt welke statistische analyses je kunt gebruiken. In SPSS, een van de meest gebruikte softwarepakketten voor statistische analyse, worden data types gecategoriseerd als nominaal, ordinaal, en scale (wat zowel interval als ratio omvat). Deze categorisatie is van essentieel belang voor het correct uitvoeren en interpreteren van statistische tests. Het correct identificeren van je data type zorgt voor betrouwbare en valide resultaten.
Data Types in SPSS: Nominaal, Ordinaal en Scale
Nominaal niveau
Nominale data zijn categorieën zonder een inherente rangorde. Denk hierbij aan kleuren (rood, blauw, groen), geslacht (man, vrouw, overig), of nationaliteit (Nederlands, Belgisch, Duits). Het enige dat je kunt doen met nominale data is tellen hoe vaak elke categorie voorkomt. Je kunt de categorieën labels geven, maar deze labels hebben geen numerieke waarde of betekenis in termen van 'meer' of 'minder'.
In SPSS worden nominale variabelen vaak gecodeerd met numerieke waarden, bijvoorbeeld 1 voor rood, 2 voor blauw, en 3 voor groen. Belangrijk is dat deze nummers slechts labels zijn. Je kunt er geen wiskundige bewerkingen mee uitvoeren, zoals het berekenen van een gemiddelde. De meest passende statistische analyses voor nominale data zijn frequentietabellen, percentages, en chi-kwadraat tests.
Voorbeeld: Stel, je voert een enquête uit onder studenten over hun favoriete studierichting. De antwoorden zijn gecategoriseerd als 'Economie', 'Rechten', 'Geneeskunde', 'Psychologie', en 'Overig'. Deze studierichtingen zijn nominale data. Je kunt tellen hoeveel studenten elke richting hebben gekozen, maar je kunt niet zeggen dat de ene richting 'beter' of 'hoger' is dan de andere.
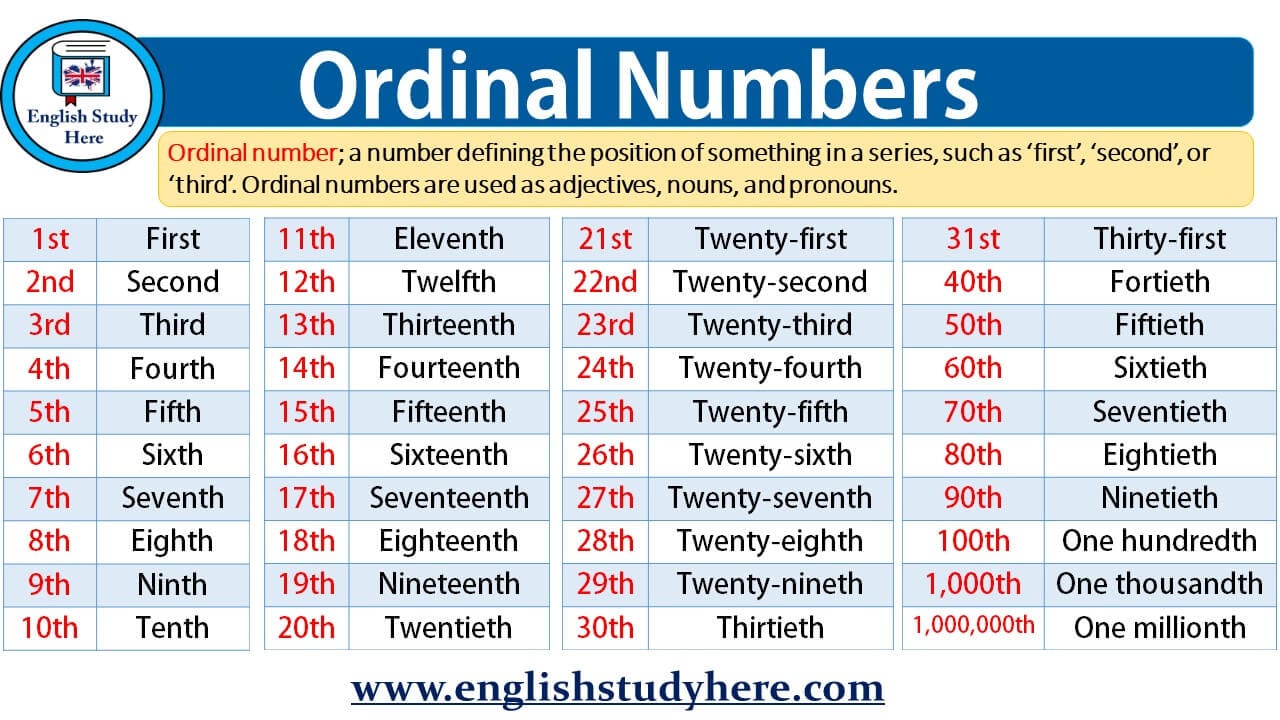
Ordinaal niveau
Ordinale data hebben wel een rangorde, maar de intervallen tussen de waarden zijn niet gelijk of bekend. Denk aan opleidingsniveau (basisschool, middelbare school, HBO, universiteit), Likert-schalen (helemaal mee oneens, mee oneens, neutraal, mee eens, helemaal mee eens), of de uitslag van een wedstrijd (eerste, tweede, derde). Je kunt de waarden ordenen, maar je kunt niet zeggen dat het verschil tussen de eerste en tweede plaats hetzelfde is als het verschil tussen de tweede en derde plaats.
In SPSS worden ordinale variabelen ook gecodeerd met nummers. Bijvoorbeeld, 1 voor basisschool, 2 voor middelbare school, 3 voor HBO, en 4 voor universiteit. In dit geval vertegenwoordigen de nummers een rangorde. Je weet dat 4 'hoger' is dan 3, maar je weet niet met hoeveel. Geschikte statistische analyses voor ordinale data omvatten mediaan, percentielen, rangcorrelatiecoëfficiënten (zoals Spearman's rho), en non-parametrische tests.
Voorbeeld: Een klanttevredenheidsonderzoek gebruikt een 5-puntsschaal: 'Zeer ontevreden', 'Ontevreden', 'Neutraal', 'Tevreden', 'Zeer tevreden'. De antwoorden vormen ordinale data. Je kunt de antwoorden ordenen van meest ontevreden naar meest tevreden, maar je kunt niet zeggen dat het verschil tussen 'Ontevreden' en 'Neutraal' hetzelfde is als het verschil tussen 'Tevreden' en 'Zeer tevreden'.
Scale niveau (Interval en Ratio)
Scale data, in SPSS, omvat zowel interval als ratio data. Dit is het hoogste meetniveau en biedt de meeste mogelijkheden voor statistische analyse. Het verschil tussen interval en ratio is dat ratio data een absoluut nulpunt heeft, terwijl interval data dat niet heeft.
Interval data hebben gelijke intervallen tussen de waarden, maar geen betekenisvol nulpunt. Een klassiek voorbeeld is temperatuur in graden Celsius of Fahrenheit. Het verschil tussen 10°C en 20°C is hetzelfde als het verschil tussen 20°C en 30°C. Echter, 0°C betekent niet dat er geen temperatuur is; het is slechts een arbitrair punt op de schaal. Je kunt optellen en aftrekken met interval data, maar niet vermenigvuldigen of delen.
Ratio data hebben gelijke intervallen en een betekenisvol nulpunt. Voorbeelden zijn lengte, gewicht, inkomen, en leeftijd. 0 cm betekent dat er geen lengte is; 0 kg betekent dat er geen gewicht is. Je kunt alle wiskundige bewerkingen (optellen, aftrekken, vermenigvuldigen, delen) uitvoeren met ratio data. Je kunt bijvoorbeeld zeggen dat iemand met een inkomen van €40.000 twee keer zoveel verdient als iemand met een inkomen van €20.000.
In SPSS worden scale variabelen gecodeerd als numerieke waarden. Je kunt alle gangbare statistische analyses uitvoeren, zoals gemiddelde, standaarddeviatie, t-tests, ANOVA, regressie, en correlatie. Het is cruciaal te beseffen dat SPSS geen onderscheid maakt tussen interval en ratio binnen de 'Scale' aanduiding, dus je moet zelf bepalen of de variabele echt een absoluut nulpunt heeft voor correcte interpretatie.
Voorbeeld (Interval): De score op een IQ-test. Het verschil tussen een IQ van 100 en 110 is hetzelfde als het verschil tussen 110 en 120. Echter, een IQ van 0 betekent niet dat iemand geen intelligentie heeft; het is een hypothetisch punt op de schaal.
Voorbeeld (Ratio): Het aantal verkochte producten per dag. Je kunt zeggen dat je vandaag twee keer zoveel producten hebt verkocht als gisteren. 0 verkochte producten betekent dat er daadwerkelijk geen producten zijn verkocht.
De Impact van Data Type op Statistische Analyse
Het kiezen van de juiste statistische test hangt sterk af van het data type. Het toepassen van een verkeerde test kan leiden tot onjuiste conclusies. Bijvoorbeeld, het berekenen van een gemiddelde voor nominale data is zinloos. Stel dat je geslacht hebt gecodeerd als 1 voor man en 2 voor vrouw. Het gemiddelde berekenen zou een getal tussen 1 en 2 opleveren, wat geen betekenisvolle interpretatie heeft.
Voor ordinale data is het berekenen van een gemiddelde ook discutabel. Hoewel het soms wordt gedaan (bijvoorbeeld bij Likert-schalen), is het belangrijk te bedenken dat de intervallen tussen de waarden niet gelijk zijn. Een mediaan of een rangcorrelatie is vaak een betere keuze.
Scale data biedt de meeste flexibiliteit. Je kunt alle gangbare statistische tests gebruiken, afhankelijk van je onderzoeksvraag en de verdeling van de data. Het is echter nog steeds belangrijk om te controleren of de data aan de aannames van de gekozen test voldoet (bijvoorbeeld normaliteit voor t-tests en ANOVA).
Data invoeren en Data Type definiëren in SPSS
In SPSS kun je het data type definiëren in de Variable View. Voor elke variabele kun je specificeren of het nominaal, ordinaal, of scale is. Dit is een essentiële stap voordat je met de analyse begint.
Wanneer je data invoert, zorg ervoor dat de waarden consistent zijn met het gekozen data type. Gebruik bijvoorbeeld numerieke codes voor nominale en ordinale variabelen, en zorg ervoor dat de codes logisch zijn en overeenkomen met de categorieën of rangorde.
Gebruik Value Labels om de numerieke codes te koppelen aan de beschrijvende labels. Dit maakt het interpreteren van de resultaten veel gemakkelijker. Bijvoorbeeld, als je geslacht hebt gecodeerd als 1 voor man en 2 voor vrouw, kun je Value Labels gebruiken om 1 te labelen als "Man" en 2 als "Vrouw".
Het correct instellen van het data type in SPSS zorgt ervoor dat de juiste statistische tests worden aangeboden en dat de resultaten correct worden geïnterpreteerd. Het is een kleine moeite met een grote impact op de betrouwbaarheid en validiteit van je onderzoek.
Real-World Data Examples
Laten we naar een paar concrete voorbeelden kijken van hoe data types worden gebruikt in verschillende onderzoekscontexten:
- Marketingonderzoek: Een marketingonderzoeker wil de effectiviteit van verschillende advertentiecampagnes vergelijken. De *type advertentie* (bijvoorbeeld print, online, televisie) is een nominale variabele. De *klanttevredenheid* gemeten op een 5-puntsschaal is een ordinale variabele. De *aantal verkopen* gegenereerd door elke campagne is een ratio variabele.
- Gezondheidszorg: Een arts wil de effectiviteit van verschillende behandelingen voor een bepaalde ziekte vergelijken. De *type behandeling* (bijvoorbeeld medicatie, fysiotherapie, chirurgie) is een nominale variabele. De *pijnscore* van de patiënt gemeten op een 10-puntsschaal is een ordinale variabele. De *hersteltijd* (in dagen) is een ratio variabele.
- Onderwijs: Een docent wil de prestaties van studenten op een examen analyseren. De *cijfer* (A, B, C, D, F) is een ordinale variabele. De *score* op het examen (op een schaal van 0 tot 100) is een ratio variabele. De *opleidingsniveau* van de ouders (basisschool, middelbare school, HBO, universiteit) is een ordinale variabele.
Door de data types correct te identificeren en te definiëren in SPSS, kunnen de onderzoekers accuraat en betrouwbaar conclusies trekken uit hun data.
Conclusie
Het begrijpen van nominale, ordinale, en scale data is essentieel voor elke onderzoeker die SPSS gebruikt. Het correct identificeren van je data type zorgt ervoor dat je de juiste statistische tests gebruikt en dat je de resultaten correct interpreteert. Neem de tijd om je data te bekijken en het data type te definiëren in SPSS voordat je met de analyse begint. Dit zal je helpen om betrouwbare en valide conclusies te trekken uit je onderzoek. Investeer in je statistische vaardigheden en je zult merken dat je data-analyse veel efficiënter en effectiever wordt. Veel succes!

Bekijk ook deze gerelateerde berichten:
- Wereld In Getallen Groep 5 Pdf
- Cast K3 En De 3 Biggetjes
- Art 300 Lid 1 Wetboek Van Strafrecht
- Wie Is De Partner Van Ahmed Aboutaleb
- Verzorgen Van Een Suprapubische Katheter
- Hoe Is Het Zonnestelsel Ontstaan
- Is Joods Een Geloof
- Dwarsdoorsnede Van De Buikholte Ter Hoogte Van De Navel
- Tovenaar In De Ban Van De Ring
- Handboek Voor Leraren 2020 Pdf